When events fail - monitoring Event Grid
Event Grid is a great service to build event driven workflows. Rather than spinning compute cycles, and cloud dollars, checking to see if something has happened we can use this service as Publish and Subscribe (aka PubSub). This is way more efficient, scalable and better user experience, I’m not checking for ‘none’ events and I’m not getting surprised by large batches if something happens and my timer hasn’t run in 15-20 minutes.
Failure Mode Analysis
Failure Mode Analysis (FMA, sometimes feels like FML!) is a process and the basic premise is that every fails eventually and you should build in resiliency from the beginning.
So in our scenario we have a on prem solution that is uploading data to our cloud based service for analysis. The local app has a circuit breaker, retry and local queuing patterns implemented to make it resilient from internet outage or an issue with Azure Storage. The local app also posts a message to a Service Bus Topic to kick off the analysis. This app is pretty old and as its running on lots of different sites on prem, so it’s difficult to update, we could have added application heartbeat but because of the aforementioned issues we are going to monitor the cloud workflow.
Our cloud application has numerous storage accounts and we need to monitor them to ensure we are receiving images on a regular basis during business hours. So we can tackle two items here, if we use Event Grid to subscribe to Blob events we can trigger the workflow and also populate an table with the container and last message received. We can then query the table and use some simple logic to determine the last time we received data.
So that all sounds great, but what happens if the Event Grid endpoint fails, back to FMA. Well that is the good news, Event Grid now supports user defined retry policies and dead letters. Retry polices are self explanatory, I can set the number of retry attempts and the timeout for when it should just give up, the defaults are 30 attempts and 24 hour timeout. The retry uses exponential backoff and randomized retry intervals, all detailed here. Dead letter is just a fancy name for the final resting place for any failed messages. I could have updated my worker function with some bad code and caused messages to fail, before this feature the events would just be lost, but now we have a robust way to catch these failures and setup a reprocess job.
Event Grid
Scene set, we are going to switch out old for new and it looks a little like this
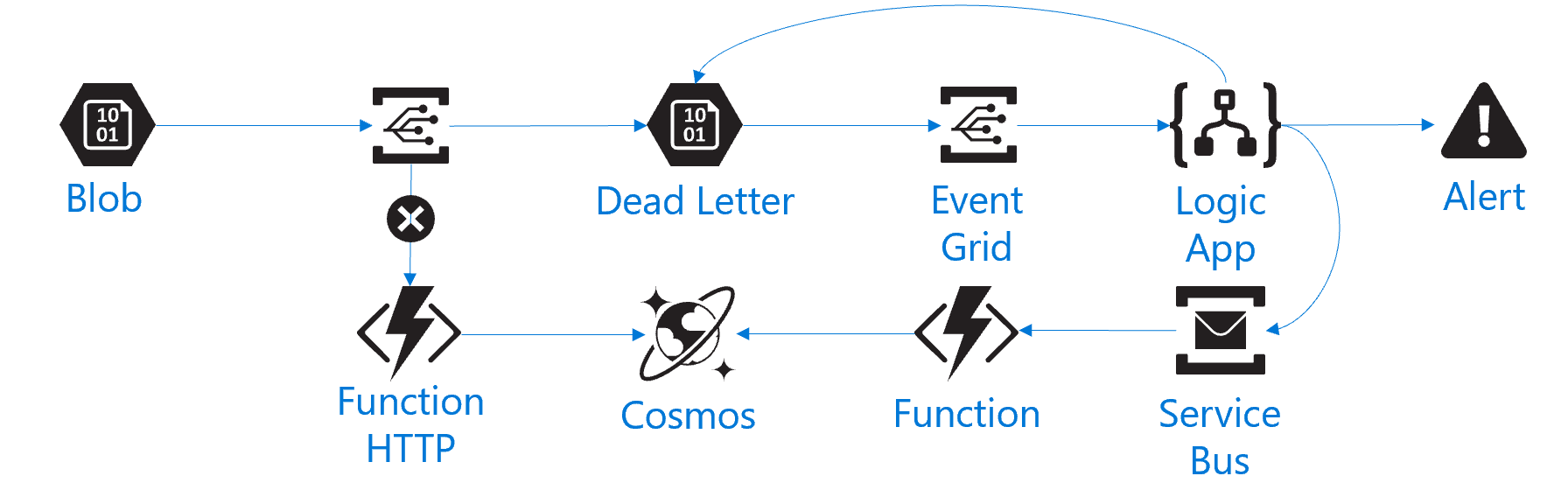
We are going to:
- Event Grid triggers a Function to run once a blob has been uploaded, this inserts some metadata into Cosmos
- If this Function should fail then Event Grid will send that failed event to blob store
- We then configured another Event Grid to listen to the Dead Letter blob storage
- So if an event fails we store the failure and trigger a Logic App
- Logic App gets the failed event and reads the payload from blob storage
- Sends and email alert and posts the message back to Service Bus
- Another Function can be enabled to read this queue and insert the failed messages into Cosmos
This gives us fault tolerance and the ability to reply failed events back into the system and maintain consistency.
Super easy to set up the retry policy